MoSCoW prioritization: a field guide for product teams
MoSCoW prioritization sorts requirements into four buckets: must, should, could, won't. Here's how to run it, where it fits, and where it lives between sprints.
TL;DR. MoSCoW prioritization sorts requirements into four buckets — must, should, could, and won’t. Must-haves ship or the release fails. Should-haves are important but defer-able. Could-haves are nice. Won’t-haves are agreed, written down, and explicitly not in scope. The framework is simple. The discipline is the “won’t” column.
Whiskers, our PM, once labelled a sprint planning poll “Things We Could Get Sued For (Must) / Things We Will Be Annoyed About (Should) / Things For The Backlog (Could) / Eugene’s Ideas (Won’t)”. The poll closed in nine minutes. That was the most honest MoSCoW prioritization exercise we have ever run, and nobody had to look up what the acronym stood for. Sub-second loads. Keyboard-first. The rest of this post is what the same exercise looks like for teams who don’t have an Eugene to blame.
What MoSCoW prioritization actually is
MoSCoW is a way of sorting work into four named categories so that everyone in the room agrees on what ships, what slips, and what is explicitly not happening. The acronym is the four words: Must, Should, Could, Won’t. The lowercase “o”s are connective tissue, added so the word reads. The method predates most of the people using it: Dai Clegg coined it at Oracle in 1994, and it became canon in the Dynamic Systems Development Method the same decade.
The reason MoSCoW survived three decades of methodology fashion is that it makes the won’t column structural rather than implied. Every prioritization framework lets you say what’s important. Only MoSCoW makes you write down what isn’t, and sign the page.
Where the name comes from
The four buckets are older than the acronym. Project teams in the 1980s had must, should, could, and would-not lists for software releases, and the would-not list was where scope creep went to die quietly. Clegg’s contribution was the spelling trick — the four initials don’t form a pronounceable word, so he added vowels and got a city. The capitalised letters carry the meaning; the lowercase letters carry the joke.
This matters because it tells you something about how the framework wants to be used. The four words have to fit on the back of a sticky note. If your variant has bolted on extra categories — must-but-only-if, should-but-Bandit-vetoed — you have built a different framework and given it the wrong name.
The four buckets, in working English
The categories are simple. The discipline is staying inside them.
| Bucket | What it means | What goes in |
|---|---|---|
| Must have | The release fails without it. | Legal/regulatory work, critical bug fixes, anything a contract names. |
| Should have | Important; painful to skip; not release-blocking. | Ergonomic improvements, secondary integrations, niceties customers will notice. |
| Could have | Welcome if there’s capacity. Easy to defer. | Polish, edge-case handling, that animation a designer keeps asking for. |
| Won’t have | Out of scope for this release. Said out loud. | Items the team considered and explicitly declined. Reviewed at the next planning round. |
Two boundaries trip teams up. Must-have is the one that inflates: every stakeholder argues their item is release-blocking. The test is brutal — if you remove this and ship anyway, do you have to issue a recall, or do you have an annoyed customer? Won’t-have is the one that gets skipped: teams maintain a should bucket and a could bucket and treat won’t as an empty category. That is the most common way the method fails. A won’t-have list with three names on it does more work than twelve must-haves.
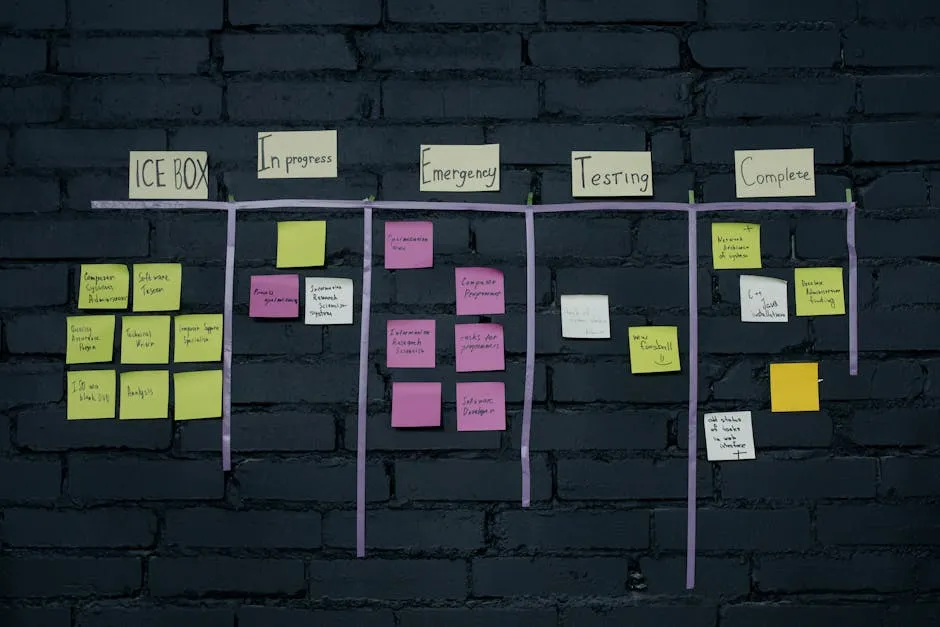
How to run a MoSCoW analysis in one session
The exercise fits in 60–90 minutes if everyone shows up with their wishlist already written down. Longer if they haven’t.
- Pre-work: dump every candidate item into one list. This is the unsorted backlog for the release window. No prioritization yet. Include the items everyone knows will slip — the won’t column needs material.
- Capacity check first. Before any bucketing, write down how much engineering time the release window actually holds. Two engineers for three weeks is six weeks. Subtract holidays, on-call rotations, and the meetings nobody can dodge. Now you have a budget.
- First pass: every item lands in a bucket. Don’t argue yet. Each item gets a colour-coded sticker or a one-word tag. Use the room’s gut.
- Capacity audit. Sum the must column against the engineering budget you wrote down in step 2. If the must column exceeds 60% of capacity, you have not prioritized — you have made a list.
- Defend the won’t column. Read it aloud. Confirm the stakeholder who suggested each item is in the room and nodding. Add their initial. The won’t column has owners, not orphans.
- Sign the artifact. PM, engineering lead, design lead, and the most senior stakeholder all add their initials and a date. Two weeks from now, somebody will try to renegotiate from memory — the signed page is what you point at.
The session ends with a one-page artifact: four columns, four sets of initials, one date. That artifact is the actual output of the exercise. The sticky notes are the by-product.
The 60/20/20/0 rule (the part nobody copies)
The original DSDM canon has a capacity allocation that most modern explainers quietly drop. The recommended split, across a release window:
- Must: up to 60% of effort.
- Should: about 20% of effort.
- Could: about 20% of effort.
- Won’t: 0% of effort.
If your must-have column eats 90% of capacity, the release has no slack — every overrun becomes a slip. If it eats 100%, the should column is fiction. Most teams discover, when they do the maths, that their honest must-haves were closer to 80% than 60%. The correction is usually painful and always correct: at least two items get moved to should, and one item moves to won’t.
A worked example, for a two-engineer, three-week sprint (roughly 6 person-weeks):
| Bucket | Person-weeks | Items |
|---|---|---|
| Must | 3.6 | SSO bug fix, payment-failure retry, GDPR data-export endpoint |
| Should | 1.2 | Search facets, audit-log export |
| Could | 1.2 | Empty-state copy refresh, theme polish |
| Won’t | 0 | Saved-search feature, plan upgrade flow rebuild, animated tour |
The won’t column is the longest. That is the point.
MoSCoW vs RICE vs Kano vs Eisenhower
Four prioritization frameworks get conflated in product team slack threads. They answer different questions.
| Framework | Question it answers | Strength | When it fails |
|---|---|---|---|
| MoSCoW | What ships this release and what doesn’t? | Forces the won’t column; releases ship with clean scope. | No scoring — argument-prone without good facilitation. |
| RICE | Which work has the best return per effort? | Numerical; ranks a backlog. | Score inflation if everyone’s reach and impact are 10/10. |
| Kano | Which work delights vs. which is table stakes? | User-research-backed; classifies expectation. | Heavy interview cost; output is qualitative. |
| Eisenhower | What do I personally do next, today? | Personal task triage. | Doesn’t scale beyond one person’s inbox. |
MoSCoW shines for release-window scope. RICE shines for backlog ranking across releases. Kano shines when you don’t know which features users care about. Eisenhower shines for an individual’s morning. Teams that mash them together usually end up with neither the clarity of MoSCoW nor the rigour of RICE — they pick one, run it, and use the others as sanity-checks.
The best prioritization framework is the one your team already half-uses. Picking up a brand-new framework mid-quarter usually costs the team a planning session in unlearning before it returns a planning session in clarity. If half your team already says “that’s a should-have” in standup, you have half a MoSCoW practice; finishing it costs less than swapping to RICE.
Where the MoSCoW analysis lives between sprints
The exercise produces a one-page artifact. That page has to be findable two weeks later, three weeks later, when somebody proposes adding scope mid-sprint. The most common failure mode is that the page lives in a Confluence space that takes 14 seconds to load on the worst day of the quarter — usually the worst day is the day somebody tries to find the artifact.
Two practical disciplines:
- One page, one prioritization, one URL. The artifact lives at a stable URL inside the team space. Future planning sessions link to it, never copy from it. Pages load in 50-150ms depending on your network, so re-opening is cheaper than copy-pasting and reasoning about which version is current.
- Last-revised + next-review dates. Stamp the page when it’s signed. Stamp it again at the next planning round. Without the dates, every renegotiation re-litigates the original — with them, the conversation starts from “what changed since 2026-04-29.”
The artifact is half of the work. The other half is keeping it where the team will actually look.
When MoSCoW is the wrong tool
Honesty section. MoSCoW is not the answer to every prioritization question.
- Backlog grooming with 400 items. MoSCoW gives you four buckets. Four buckets across 400 items means 100 things in the must column and a mutiny by Wednesday. Use RICE or weighted shortest job first; reach for MoSCoW once the list is down to a release window.
- One-person task lists. The framework was designed for a team to agree on scope, not for an individual to decide what to do after lunch. Eisenhower is faster for that.
- Roadmap-level decisions (six months out). MoSCoW is a release-scope tool. For roadmap framing, Kano or jobs-to-be-done usually fits better — the four-bucket sort is too coarse when the question is which markets we’re in next year.
- A scoring engine for a 400-item backlog. Raccoon Page is a wiki, not a prioritization tool. If you need a system that ranks four hundred backlog items numerically, run that work in Productboard or Aha! — our slash-command palette is the wrong UI for spreadsheet-shaped scoring. The MoSCoW artifact belongs in a wiki; the scoring engine usually doesn’t.
The framework you reach for first should match the decision shape. MoSCoW is the right answer when the decision shape is what ships in this release window. It is the wrong answer when the decision shape is anything else.
Things people actually ask
Where does the term MoSCoW come from? Dai Clegg created it at Oracle in 1994. The four capital letters spell Must, Should, Could, Won’t; the lowercase “o”s are connective tissue added so the word reads as a city. The method became canon in the DSDM agile framework around the same time.
What’s the difference between should-have and could-have? Should-have is important — you’d feel the absence in week two. Could-have is welcome — you might not notice if it slipped. The test is whether a customer or stakeholder would file a complaint. Should-haves attract complaints; could-haves attract requests.
How is MoSCoW different from RICE? MoSCoW answers what ships in this release? with four named buckets. RICE answers which item ranks higher? with a numerical score (Reach × Impact × Confidence ÷ Effort). MoSCoW is faster for release-window scope; RICE is sharper for cross-release backlog ranking. Many teams run RICE on the backlog and MoSCoW on the release window.
What goes in the won’t have category? Items the team considered and explicitly declined for this release, with the stakeholder’s agreement on record. The won’t column has named owners and a planned review date. It is not the same as the backlog — the backlog is everything not yet decided; won’t have is everything decided against.
How long should a MoSCoW session take? 60–90 minutes if everyone shows up with a wishlist. Longer if the wishlist is being assembled live. If the session is running past two hours, the team is not prioritizing — it’s discovering scope. Stop, gather it, regroup tomorrow.
Can MoSCoW be combined with sprint planning? Yes — and the cleanest pairing is to run MoSCoW once per release-window kickoff, then carry the artifact into every sprint inside the window. Each sprint pulls from the must column first, then should, then could. The won’t column never gets pulled from; it gets re-reviewed at the next planning kickoff.
Does MoSCoW work for non-software teams? Yes. Marketing teams use it for campaign scope; ops teams use it for quarterly initiatives; legal teams use it for release-gate compliance items. The four-bucket sort is release-agnostic — the “release” can be a launch, a campaign window, or a fiscal quarter.
What if my team disagrees on must-have items? That’s the entire point. The exercise surfaces hidden priority conflicts in 60–90 minutes instead of three sprints from now. When two stakeholders defend the same item into must, the resolution conversation is the deliverable — not the bucket.
The framework is older than most of your teammates. The
discipline is keeping the won’t column populated and the
artifact findable. We built Raccoon Page so the
prioritization document loads in under a second and the next
review date is one keystroke away — Cmd+K, type moscow,
land on the page. The framework you reach for first should
match the decision shape. Then the artifact should be
somewhere your team will actually go. If you want a template
to start from, our
feature specification template
ships with a MoSCoW section built in; the
team charter post explains why the
revision date matters more than the framework does. Free for
super-lean teams. No credit card required.
Written by The Editorial Raccoon — house style for Raccoon Page. Numbers and claims pulled from product reality; jokes pulled from the Raccoon Corp canon. No raccoons were quoted in real life.